merge
This commit is contained in:
commit
e4aaca39ed
1 changed files with 15 additions and 15 deletions
28
report.md
28
report.md
|
|
@ -2,11 +2,11 @@
|
|||
|
||||
## 1.1. Goal
|
||||
|
||||
The goal with this project was to give a computer a drawing of either a cat's or a dog's face and let it with high probability predict if it is a cat or a dog shown in that drawing.
|
||||
The goal of this project was to give a computer a drawing of either a cat's or a dog's face and let it recognize with high probability whether a cat or a dog is shown.
|
||||
|
||||
## 1.2. Scope
|
||||
|
||||
First I was thinking that I would get lots of people to draw cat and dog faces for me which I later found out was far to time consuming. Therefore I had to change the scope from recognizing random peoples drawings to recognizing my own drawings, which is obviously easier. Nevertheless everything else didn't change that much, I just would get better results.
|
||||
First I thought that I would get lots of people to draw cat and dog faces for me, but I later realized that it was far too time consuming. Therefore I had to change the scope from recognizing random peoples drawings to recognizing my own drawings, which is obviously easier. Everything else did not change that much, I would just get better results.
|
||||
|
||||
# 2. Preparation
|
||||
|
||||
|
|
@ -14,25 +14,25 @@ First I was thinking that I would get lots of people to draw cat and dog faces f
|
|||
|
||||

|
||||
|
||||
I drew eight A4 sheets of such cat and dog faces which resulted in 64 drawings of dog faces and 60 drawings of cat faces. Then I took pictures of them with my digital camera.
|
||||
I drew eight A4 sheets of such cat and dog faces which resulted in 64 dog faces and 60 cat faces. Then I took pictures of them with my digital camera.
|
||||
|
||||
There was a huge difference in quality between the pictures I took with my iPhone 4 cammera and the ones I took with my Nikon D5000. In fact I wasn't able to use the pictures I took with the iPhone because it was impossible to find straight lines in them.
|
||||
There was a huge difference in quality between the pictures I took with my iPhone 4 camera and the ones I took with my Nikon D5000. In fact I was not able to use the pictures I took with the iPhone because it was impossible to find straight lines in them.
|
||||
|
||||
You can see here the result, one with the iPhone image as a source and the other with the Nikon one:
|
||||
You can see the result here, one with the iPhone image as a source and the other with the Nikon image:
|
||||
|
||||

|
||||
|
||||
## 2.2. Photoshop
|
||||
|
||||
I had to clean up the drawings so it would be easier for the algorithm later on to find everything. What I did was I opened the pictures of the drawings in Photoshop and played with the contrast and brightness.
|
||||
I cleaned up the drawings so it would be easier for the algorithm to find everything. I opened the pictures of the drawings in Photoshop and played with the contrast and brightness settings.
|
||||
|
||||
Then I cut out one drawing after another from the big image and saved it as a black and white PNG image without dither.
|
||||
Then I cut out all the drawings from the big image and saved them as a black and white PNG images without dither.
|
||||
|
||||

|
||||
|
||||
## 2.3. Resizing
|
||||
|
||||
I wrote a small shellscript which would take all pictures resize them proportionally to a max width and height of 200 px and fill up the missibg borders with a white background color. To do that I used the [ImageMagick](www.imagemagick.org) software suite:
|
||||
I wrote a small shellscript which would take all pictures and resize them proportionally to a max width and height of 200 px. It also fills up the missing borders with a white background color. To do that I used the [ImageMagick](www.imagemagick.org) software suite:
|
||||
|
||||
<pre>#!/bin/sh
|
||||
|
||||
|
|
@ -50,11 +50,11 @@ do
|
|||
$NEW/$i
|
||||
done</pre>
|
||||
|
||||
After that all the images had uniform size and colors so now I was able to compare them in a meaningfull way.
|
||||
After that all the images had uniform sizes and colors so that I was able to compare them in a meaningful way.
|
||||
|
||||
# 3. Feature extraction
|
||||
|
||||
The next step was to extract the features from the images which means to find something in the pictures which I was able to count and it would be unique enough to find a difference between cats and dogs but broad enough so all dogs would fall into one category and all cats to another.
|
||||
The next step was to extract the features from the images. In other words find things in the pictures that would be unique enough to make a difference between cats and dogs but broad enough so that all dogs would fall into one category and all cats into the other.
|
||||
|
||||
## 3.1. Straight lines
|
||||
|
||||
|
|
@ -62,13 +62,13 @@ The first thing which came to mind was counting and doing other stuff with strai
|
|||
|
||||
### 3.1.1 Canny edge detector
|
||||
|
||||
I used a the edge detector algorithm called Canny to preprocess the images which like its name says finds edges in images. Because of my preparation with Photoshop it was quite easy for it to find them. It is not easy to see that step with my drawings, here a picture how it looks like if you do that with a photo instead:
|
||||
I used an edge detector algorithm called Canny to preprocess the images which - as the name implies - finds edges in images. Because of my preparation with Photoshop it was quite easy for it to find them. It is not easy to see this step with my drawings, so here is a picture of how it looks like when you do this with a photo instead:
|
||||
|
||||

|
||||
|
||||
What it does is basically it does noise reduction with a gausian filter and then finds the intentisty gradians of the image with help of some trigonometry.
|
||||
It basically reduces noise with a gausian filter and then finds the intentisty gradians of the image with help of some trigonometry.
|
||||
|
||||
I didn't implement the algorithm myself, instead I used the [OpenCV implementation](http://docs.opencv.org/doc/tutorials/imgproc/imgtrans/canny_detector/canny_detector.html).
|
||||
I did not implement the algorithm myself, instead I used the [OpenCV implementation](http://docs.opencv.org/doc/tutorials/imgproc/imgtrans/canny_detector/canny_detector.html).
|
||||
|
||||
### 3.1.2 Hough transform
|
||||
|
||||
|
|
@ -95,7 +95,7 @@ I also extracted the amount of black pixels in the image to use it as a possible
|
|||
# 4. _k_-nearest neighbor algorithm
|
||||
|
||||
I chose to use the _k_-Nearest Neighbors algorithm which only locally looks at the neighbors of the document in a radius predefined by the user. It assumes that the document is of the same category as the highest number of neighbors within this radius.
|
||||
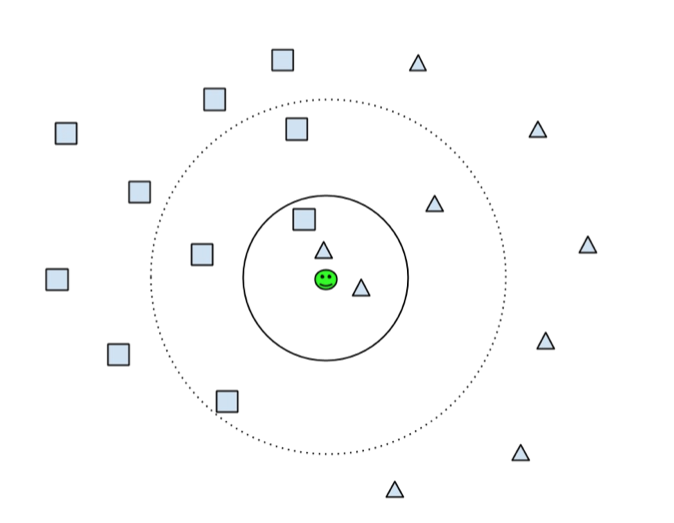
In the following figure you can see that depending if the user choses k = 3, as showed by the solid line, the algorithm will conclude that the document in the center (green smiley) is of the type triangle because most of this three neighbors are triangles. If on the other hand the user choses k = 7, as showed by the dotted line, then the amount of neighbors which are rectangles is greater as the amount of neighbors which are triangles, so it concludes that the smiley is of type rectangle.
|
||||
In the following figure you can see that depending if the user choses k = 3, as showed by the solid line, the algorithm will conclude that the document in the center (green smiley) is of the type triangle because most of this three neighbors are triangles. If on the other hand the user choses k = 7, as showed by the dotted line, then the amount of neighbors which are rectangles is greater as the amount of neighbors which are triangles, so it concludes that the smiley is of type rectangle.
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue