finished correcting
This commit is contained in:
parent
a8a49402a5
commit
ec6f64c9a0
1 changed files with 9 additions and 9 deletions
18
report.md
18
report.md
|
|
@ -66,7 +66,7 @@ I used an edge detector algorithm called Canny to preprocess the images which -
|
|||
|
||||

|
||||
|
||||
It basically reduces noise with a gausian filter and then finds the intentisty gradians of the image with help of some trigonometry.
|
||||
It basically removes noise with a gausian filter and then finds the intentisty gradians of the image with help of some trigonometry.
|
||||
|
||||
I did not implement the algorithm myself, instead I used the [OpenCV implementation](http://docs.opencv.org/doc/tutorials/imgproc/imgtrans/canny_detector/canny_detector.html).
|
||||
|
||||
|
|
@ -76,11 +76,11 @@ To find the lines I used the [Hough transform](https://en.wikipedia.org/wiki/Hou
|
|||
|
||||

|
||||
|
||||
What it basically does is grouping edges, which can be imperfect, to object candidates by performing an explicit voting procedure. Detecting straight lines can be done by describing them as <code>y = mx + b</code> where <code>m</code> is the slope of the line and <code>b</code> is the intercept. The line is not represented by descrete points <code>(x1,y1)(x2,y2)</code> but instead as a <code>point(x,y)</code> in the parameter space, which makes detection of lines which are a bit off possible. In practice it is still more complicated, please read the [Wikipedia article](https://en.wikipedia.org/wiki/Hough_transform) about it.
|
||||
It essentially groups edges, which can be imperfect, to object candidates by performing an explicit voting procedure. Detecting straight lines can be done by describing them as <code>y = mx + b</code> where <code>m</code> is the slope of the line and <code>b</code> is the intercept. The line is not represented by descrete points <code>(x1,y1)(x2,y2)</code> but instead as a <code>point(x,y)</code> in the parameter space, which makes detection of lines which are a bit off possible. In practice it is still more complicated, please read the [Wikipedia article](https://en.wikipedia.org/wiki/Hough_transform) about it.
|
||||
|
||||
Because of lack of time I didn't implement it myself but used the probabilistic [OpenCV implementation](http://docs.opencv.org/modules/imgproc/doc/feature_detection.html?highlight=houghlinesp#houghlinesp).
|
||||
Because of lack of time I did not implement it myself but used the probabilistic [OpenCV implementation](http://docs.opencv.org/modules/imgproc/doc/feature_detection.html?highlight=houghlinesp#houghlinesp).
|
||||
|
||||
## 3.2. Lines features
|
||||
## 3.2. Line features
|
||||
|
||||
I extracted these features from the lines:
|
||||
|
||||
|
|
@ -90,7 +90,7 @@ I extracted these features from the lines:
|
|||
|
||||
## 3.3. Other features
|
||||
|
||||
I also extracted the amount of black pixels in the image to use it as a possible feature which wasn't using the extracted lines.
|
||||
I also extracted the amount of black pixels in the image to use it as a possible feature which was not using the extracted lines.
|
||||
|
||||
# 4. _k_-nearest neighbor algorithm
|
||||
|
||||
|
|
@ -99,7 +99,7 @@ I chose to use the _k_-Nearest Neighbors algorithm which only locally looks at t
|
|||
|
||||
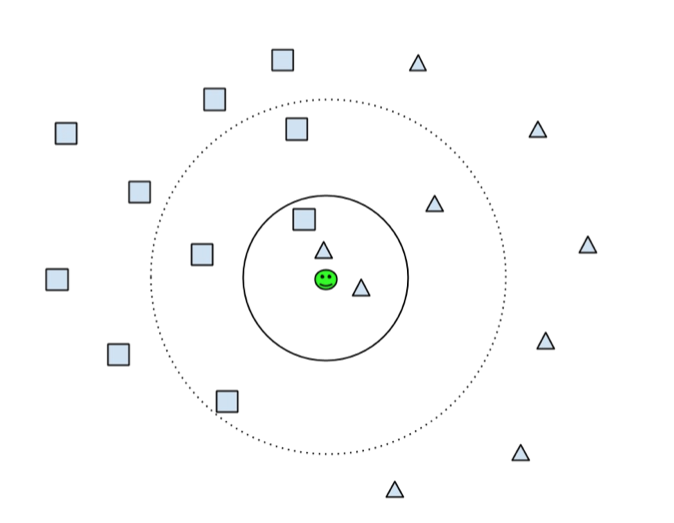
|
||||
|
||||
In the picture above you see how it would look with two dimensions. I have been using four features so the algorithm had to check the distance to the neighbours in four dimensions. This isn't really more difficult, it is just more to calculate.
|
||||
In the picture above you see how it would look with two dimensions. I have been using four features so the algorithm had to check the distance to the neighbours in four dimensions. This is not really more difficult, it is just more to calculate.
|
||||
|
||||
# 5. Results
|
||||
|
||||
|
|
@ -107,7 +107,7 @@ The results were quite encouraging, I assume it is because I only used one style
|
|||
|
||||
## 5.1. k-fold Cross-validation
|
||||
|
||||
I used 10 fold cross-validation for every test I did, which means that I used 90% of the available data for the learning algorithms and then the remaining 10% to test how they performed. I repeated this ten times until all data has been used for testing once.
|
||||
I used 10 fold cross-validation for every test I did, which means that I used 90% of the available data for the learning algorithms and then the remaining 10% to test how they performed. I repeated this ten times until all data had been used for testing once.
|
||||
|
||||
## 5.2. Results with all features
|
||||
|
||||
|
|
@ -115,11 +115,11 @@ When I used all of the features and three nearest neighbours I got amazing 100%
|
|||
|
||||
## 5.3. Results with a reduced feature set
|
||||
|
||||
Therefor I tried to reduce the features to check if it would perform worse.
|
||||
Therefore I tried to reduce the features to check if it would perform worse.
|
||||
|
||||
1. When I removed the information about the amount of black pixels basically nothing happened.
|
||||
2. When I removed the information about the amount of lines and average length at least I got a couple of wrong categorized images, the accuracy went down to 95%.
|
||||
3. When I removed the information about the average angle of the lines, that was when I got significant errors. The accuracy dropped down to about 60%, which is still better then pure chanse.
|
||||
3. When I removed the information about the average angle of the lines, that was when I got significant errors. The accuracy dropped down to about 60%, which is still better then pure chance.
|
||||
|
||||
So it seems like the best feature to detect cat and dog face drawings done by me was the average angle of the straight lines in the image.
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue