5.8 KiB
Чёрная дыра бэктрекинга [todo]
Некоторые регулярные выражения, с виду являясь простыми, могут выполняться оооочень долго, и даже подвешивать браузер.
[cut] Например, попробуйте пример ниже в Chrome или IE (осторожно, подвесит браузер!):
//+ run
alert( '123456789012345678901234567890z'.match(/(\d+)*$/) );
Некоторые движки регулярных выражений (Firefox) справляются с таким регэкспом, а некоторые (IE, Chrome) -- нет.
В чём же дело, что не так с регэкспом?
Да с регэкспом-то всё так, синтаксис вполне допустимый. Проблема в том, как выполняется поиск по нему.
Для краткости рассмотрим более короткую строку: 1234567890z:
- Первым делом, движок регэкспов пытается найти
\d+. Плюс+является жадным по умолчанию, так что он хватает все цифры, какие может.Затем движок пытается применить звёздочку вокруг скобок
(\d+)*, но больше цифр нет, так что звёздочка не даёт повторений.После этого в паттерне остаётся
$, а в тексте -- символz.
Так как соответствия нет, то жадный плюс
+отступает на один символ (бэктрекинг, зелёная стрелка на рисунке выше). - После бэктрекинга,
\d+содержит всё число, кроме последней цифры. Затем движок снова пытается найти совпадение, уже с новой позиции (`9`).Звёздочка
(\d+)*теперь может быть применена -- она даёт ещё одно число9:
Движок пытается найти
$, но это ему не удаётся -- на его пути опятьz:
Так как совпадения нет, то поисковой движок отступает назад ещё раз.
- Теперь первое число
\d+будет содержать 8 цифр, а остаток строки90становится вторым\d+: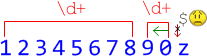
Увы, всё ещё нет соответствия для
$.Поисковой движок снова должен отступить назад. При этом последний жадный квантификатор отпускает символ. В данном случае это означает, что укорачивается второй
\d+, до одного символа9. - Теперь движок регулярных выражений снова может применить звёздочку и находит третье число
\d+: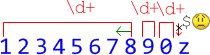
...И снова неудача. Второе и третье
\d+отступили по-максимуму, так что сокращается снова первое число. - Теперь есть 7 цифр в первом
\d+. Поисковой движок видит место для второго\d+, теперь уже с позиции 8:
Так как совпадения нет, второй
\d+отступает назад.... - ...И так далее, легко видеть, что поисковой движок будет перебирать *все возможные комбинации*
\d+в числе. А их много.
На этом месте умный читатель может воскликнуть: "Бэктрекинг? Давайте включим ленивый режим -- и не будет никакого бэктрекинга!"
Что ж, заменим \d+ на \d+? и посмотрим (аккуратно, может подвесить браузер):
//+ run
alert( '123456789012345678901234567890z'.match(/(\d+?)*$/) );
Не помогло!
Ленивые регулярные выражения делают то же самое, но в обратном порядке.
Просто подумайте о том, как будет в этом случае работать поисковой движок.
Некоторые движки регулярных выражений, например Firefox, содержат хитрые проверки, в дополнение к алгоритму выше, которые позволяют избежать бесконечного перебора или кардинально ускорить его, но все движки и не всегда.