Checked some spelling further along in the article files. Made some small grammatical fixes, but mostly spelling.
7.3 KiB
Character classes
Consider a practical task -- we have a phone number "+7(903)-123-45-67", and we need to find all digits in that string. Other characters do not interest us.
A character class is a special notation that matches any symbol from the set.
[cut]
For instance, there's a "digit" class. It's written as \d. We put it in the pattern, and during the search any digit matches it.
For instance, the regexp pattern:/\d/ looks for a single digit:
let str = "+7(903)-123-45-67";
let reg = /\d/;
alert( str.match(reg) ); // 7
The regexp is not global in the example above, so it only looks for the first match.
Let's add the g flag to look for all digits:
let str = "+7(903)-123-45-67";
let reg = /\d/g;
alert( str.match(reg) ); // array of matches: 7,9,0,3,1,2,3,4,5,6,7
Most used classes: \d \s \w
That was a character class for digits. There are other character classes as well.
Most used are:
\d("d" is from "digit")- A digit: a character from
0to9. \s("s" is from "space")- A space symbol: that includes spaces, tabs, newlines.
\w("w" is from "word")- A "wordly" character: either a letter of English alphabet or a digit or an underscore. Non-english letters (like cyrillic or hindi) do not belong to
\w.
For instance, pattern:\d\s\w means a digit followed by a space character followed by a wordly character, like "1 Z".
A regexp may contain both regular symbols and character classes.
For instance, pattern:CSS\d matches a string match:CSS with a digit after it:
let str = "CSS4 is cool";
let reg = /CSS\d/
alert( str.match(reg) ); // CSS4
Also we can use many character classes:
alert( "I love HTML5!".match(/\s\w\w\w\w\d/) ); // 'HTML5'
The match (each character class corresponds to one result character):
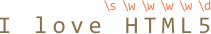
Word boundary: \b
The word boundary pattern:\b -- is a special character class.
It does not denote a character, but rather a boundary between characters.
For instance, pattern:\bJava\b matches match:Java in the string subject:Hello, Java!, but not in the script subject:Hello, JavaScript!.
alert( "Hello, Java!".match(/\bJava\b/) ); // Java
alert( "Hello, JavaScript!".match(/\bJava\b/) ); // null
The boundary has "zero width" in a sense that usually a character class means a character in the result (like a wordly or a digit), but not in this case.
The boundary is a test.
When regular expression engine is doing the search, it's moving along the string in an attempt to find the match. At each string position it tries to find the pattern.
When the pattern contains pattern:\b, it tests that the position in string fits one of the conditions:
- String start, and the first string character is
\w. - String end, and the last string character is
\w. - Inside the string: from one side is
\w, from the other side -- not\w.
For instance, in the string subject:Hello, Java! the following positions match \b:
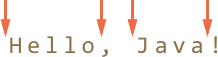
So it matches pattern:\bHello\b and pattern:\bJava\b, but not pattern:\bHell\b (because there's no word boundary after l) and not Java!\b (because the exclamation sign is not a wordly character, so there's no word boundary after it).
alert( "Hello, Java!".match(/\bHello\b/) ); // Hello
alert( "Hello, Java!".match(/\Java\b/) ); // Java
alert( "Hello, Java!".match(/\Hell\b/) ); // null
alert( "Hello, Java!".match(/\Java!\b/) ); // null
Once again let's note that pattern:\b makes the searching engine to test for the boundary, so that pattern:Java\b finds match:Java only when followed by a word boundary, but it does not add a letter to the result.
Usually we use \b to find standalone English words. So that if we want "Java" language then pattern:\bJava\b finds exactly a standalone word and ignores it when it's a part of "JavaScript".
Another example: a regexp pattern:\b\d\d\b looks for standalone two-digit numbers. In other words, it requires that before and after pattern:\d\d must be a symbol different from \w (or beginning/end of the string).
alert( "1 23 456 78".match(/\b\d\d\b/g) ); // 23,78
The word boundary check `\b` tests for a boundary between `\w` and something else. But `\w` means an English letter (or a digit or an underscore), so the test won't work for other characters (like cyrillic or hieroglyphs).
Reverse classes
For every character class there exists a "reverse class", denoted with the same letter, but uppercased.
The "reverse" means that it matches all other characters, for instance:
\D- Non-digit: any character except
\d, for instance a letter. \S- Non-space: any character except
\s, for instance a letter. \W- Non-wordly character: anything but
\w. \B- Non-boundary: a test reverse to
\b.
In the beginning of the chapter we saw how to get all digits from the phone subject:+7(903)-123-45-67. Let's get a "pure" phone number from the string:
let str = "+7(903)-123-45-67";
alert( str.match(/\d/g).join('') ); // 79031234567
An alternative way would be to find non-digits and remove them from the string:
let str = "+7(903)-123-45-67";
alert( str.replace(/\D/g, "") ); // 79031234567
Spaces are regular characters
Please note that regular expressions may include spaces. They are treated like regular characters.
Usually we pay little attention to spaces. For us strings subject:1-5 and subject:1 - 5 are nearly identical.
But if a regexp does not take spaces into account, it won' work.
Let's try to find digits separated by a dash:
alert( "1 - 5".match(/\d-\d/) ); // null, no match!
Here we fix it by adding spaces into the regexp:
alert( "1 - 5".match(/\d - \d/) ); // 1 - 5, now it works
Of course, spaces are needed only if we look for them. Extra spaces (just like any other extra characters) may prevent a match:
alert( "1-5".match(/\d - \d/) ); // null, because the string 1-5 has no spaces
In other words, in a regular expression all characters matter. Spaces too.
A dot is any character
The dot "." is a special character class that matches any character except a newline.
For instance:
alert( "Z".match(/./) ); // Z
Or in the middle of a regexp:
let reg = /CS.4/;
alert( "CSS4".match(reg) ); // CSS4
alert( "CS-4".match(reg) ); // CS-4
alert( "CS 4".match(reg) ); // CS 4 (space is also a character)
Please note that the dot means "any character", but not the "absense of a character". There must be a character to match it:
alert( "CS4".match(/CS.4/) ); // null, no match because there's no character for the dot
Summary
We covered character classes:
\d-- digits.\D-- non-digits.\s-- space symbols, tabs, newlines.\S-- all but\s.\w-- English letters, digits, underscore'_'.\W-- all but\w.'.'-- any character except a newline.
If we want to search for a character that has a special meaning like a backslash or a dot, then we should escape it with a backslash: pattern:\.
Please note that a regexp may also contain string special characters such as a newline \n. There's no conflict with character classes, because other letters are used for them.